.png)



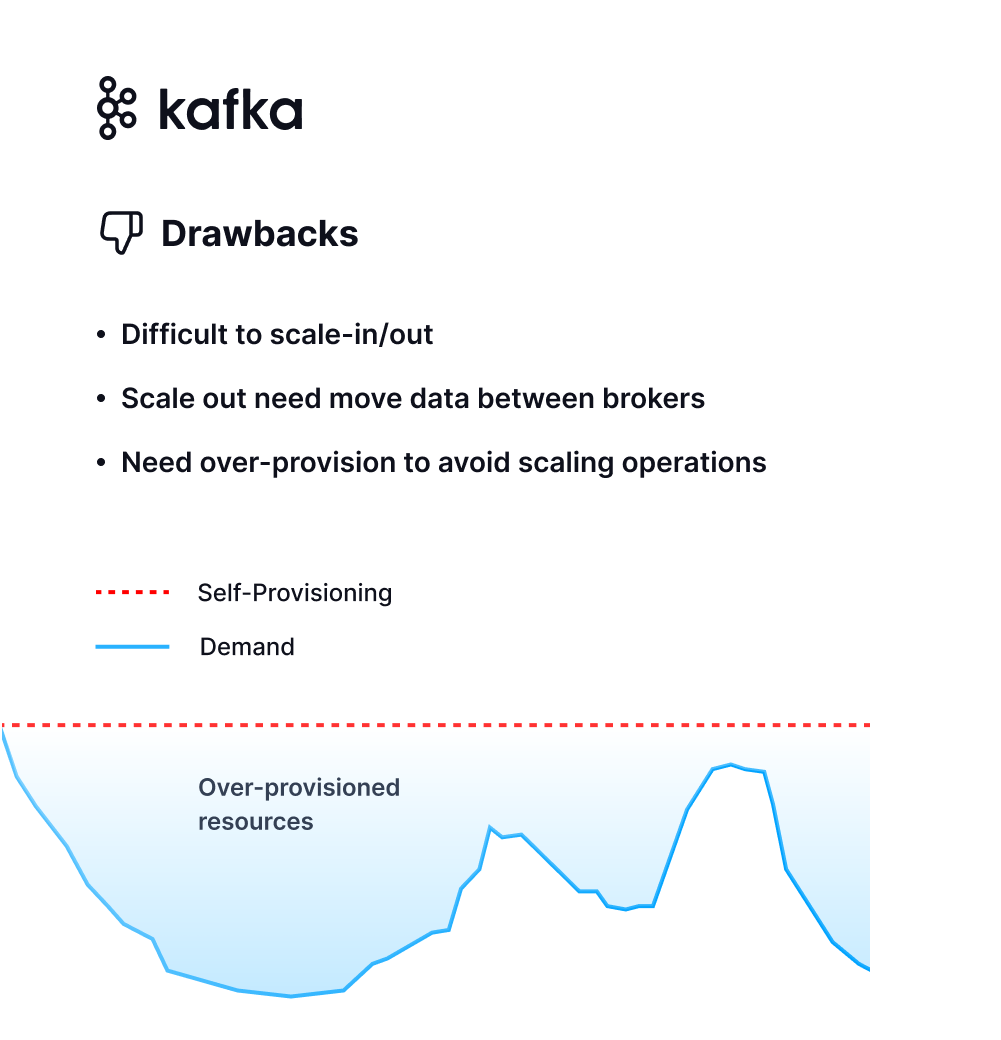
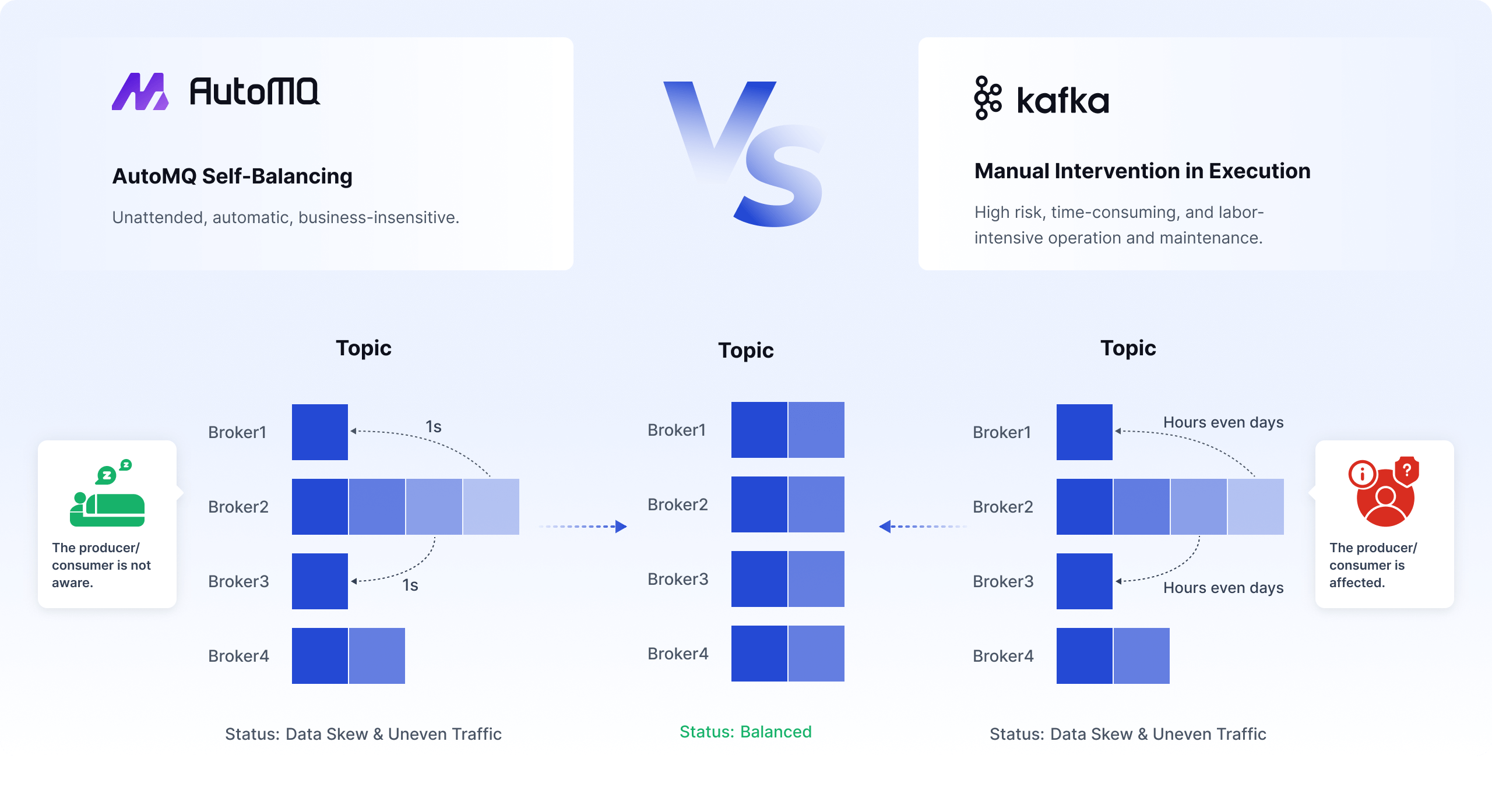
Difficult to Scale In/Out
Scaling Kafka in or out requires the manual creation of partition migration strategies and replication of partition data. This process is not only high-risk and resource-intensive but also time-consuming.

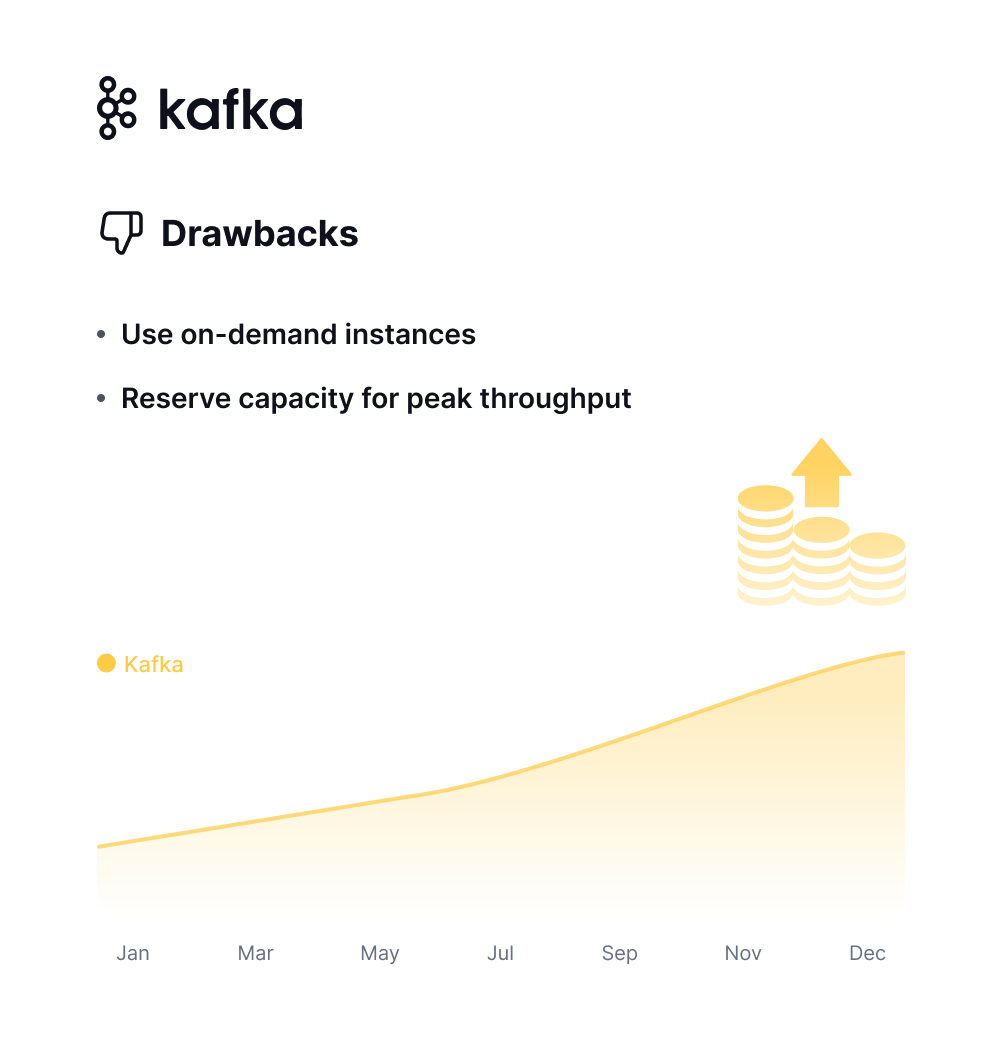
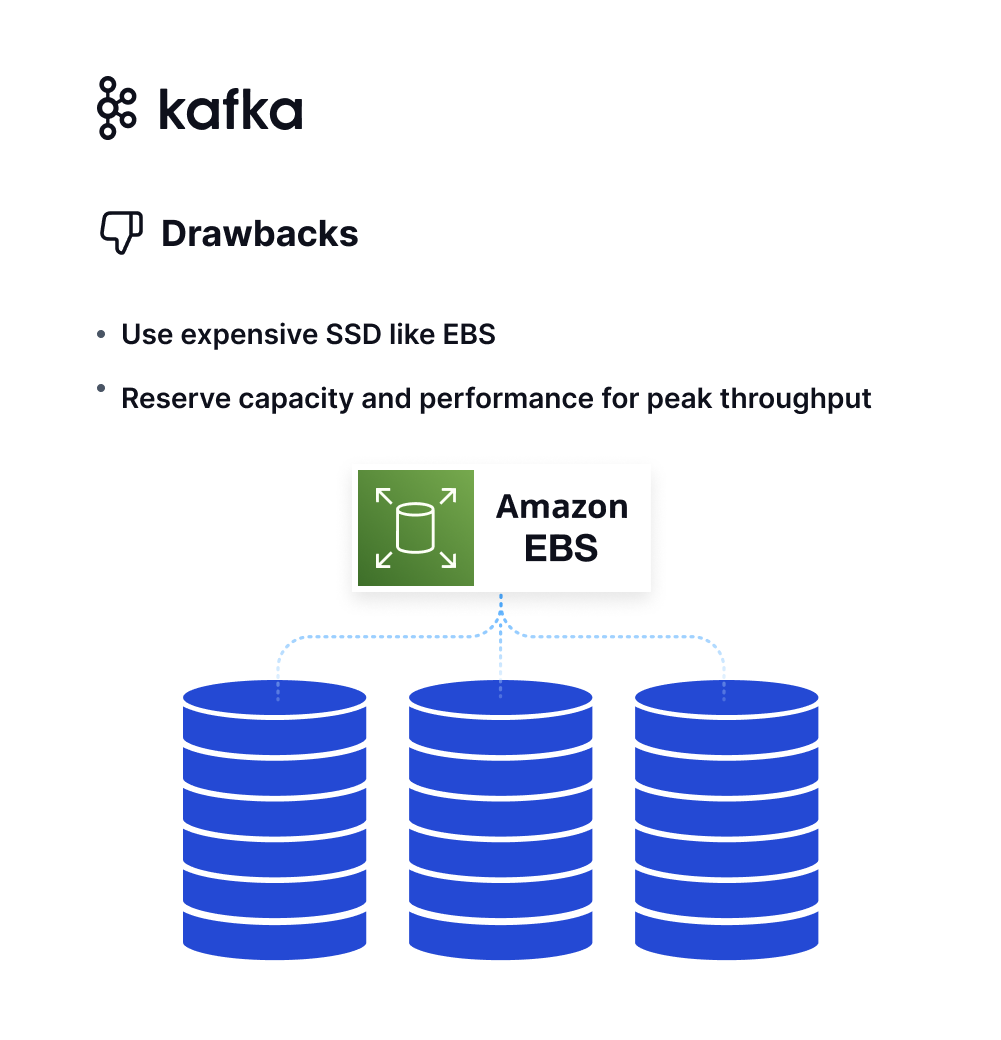
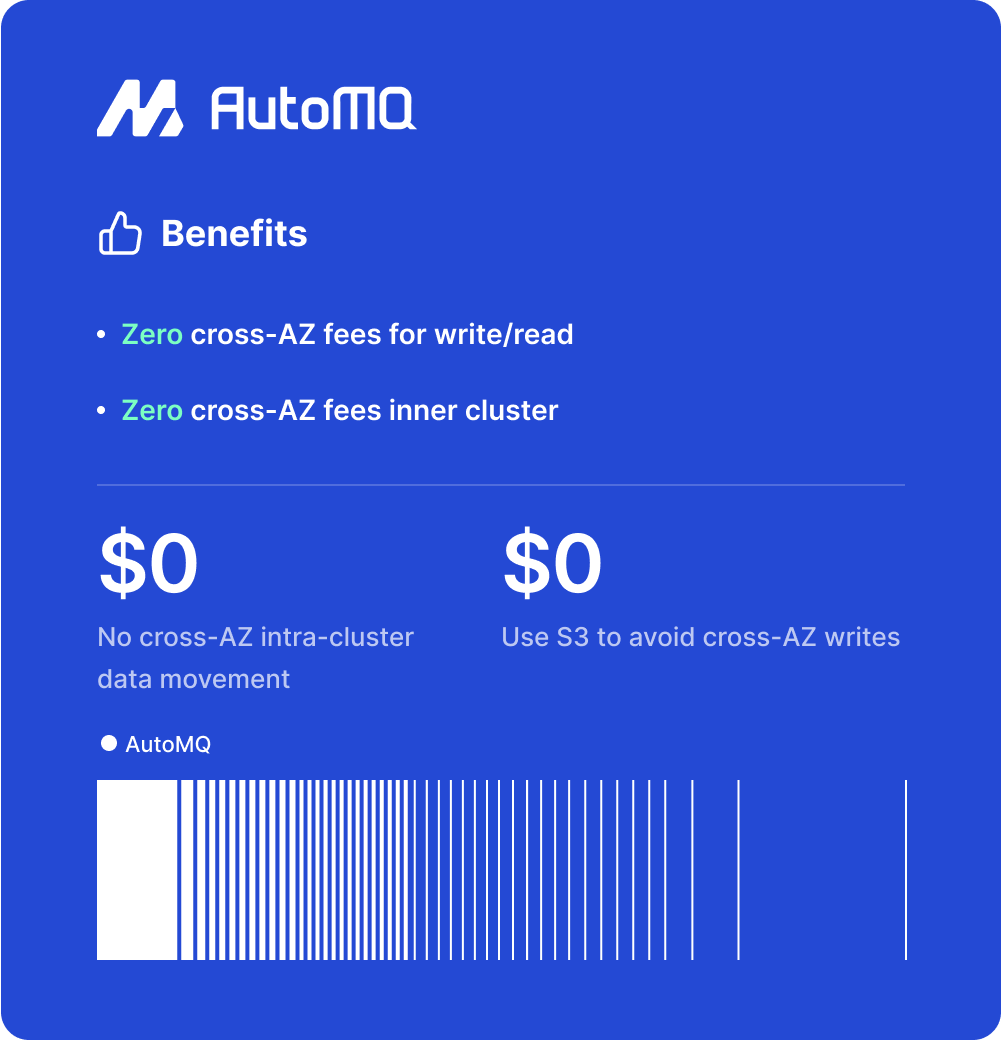
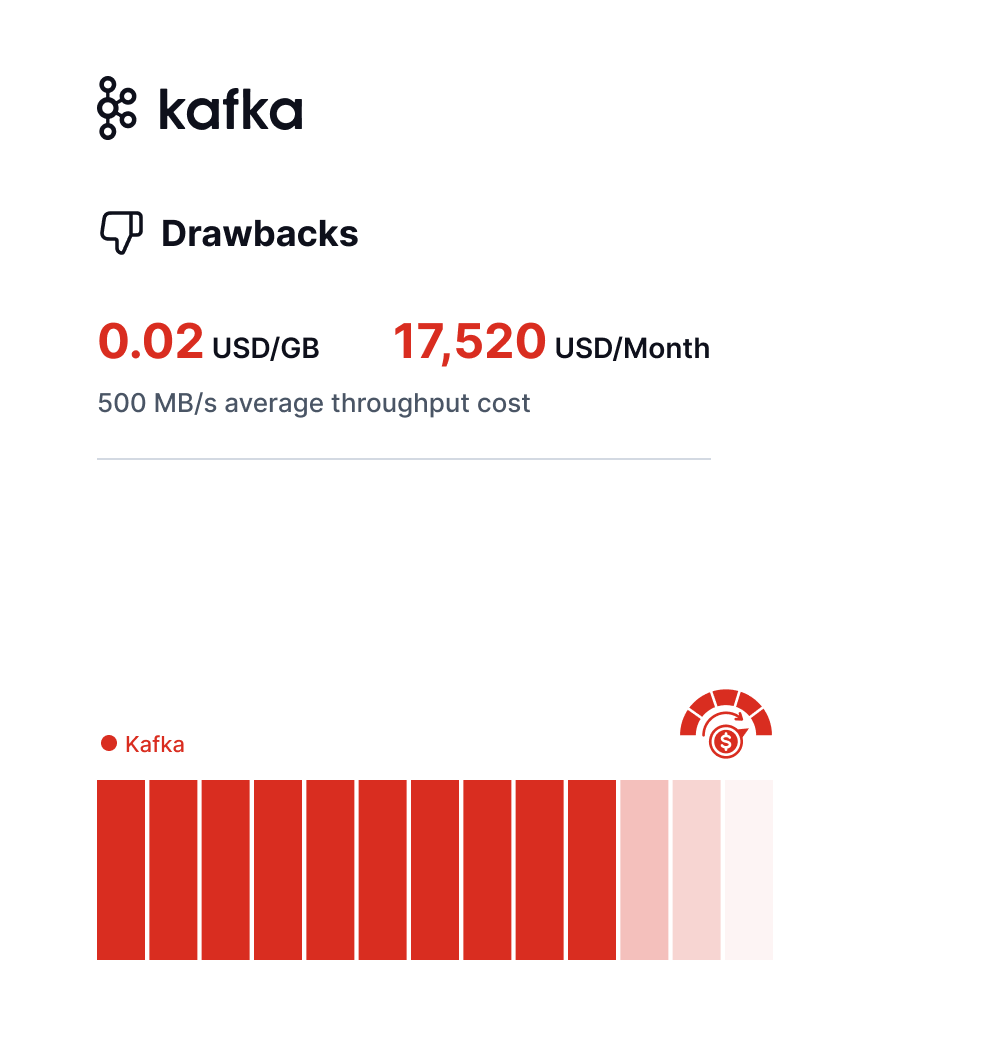
Expensive
Computation and storage are tightly coupled in Kafka, meaning they must be scaled in or out simultaneously. This coupling often results in resource wastage. Additionally, to guarantee low latency and high throughput, users often incur significant storage expenses.

Weak Self-Healing Ability
Kafka is unable to automatically recover from abnormal conditions like data hotspots and uneven capacity distribution.

Data Skew
Kafka is unable to automatically address issues like data skew and hotspot partitions, resulting in performance degradation and operational inefficiencies.

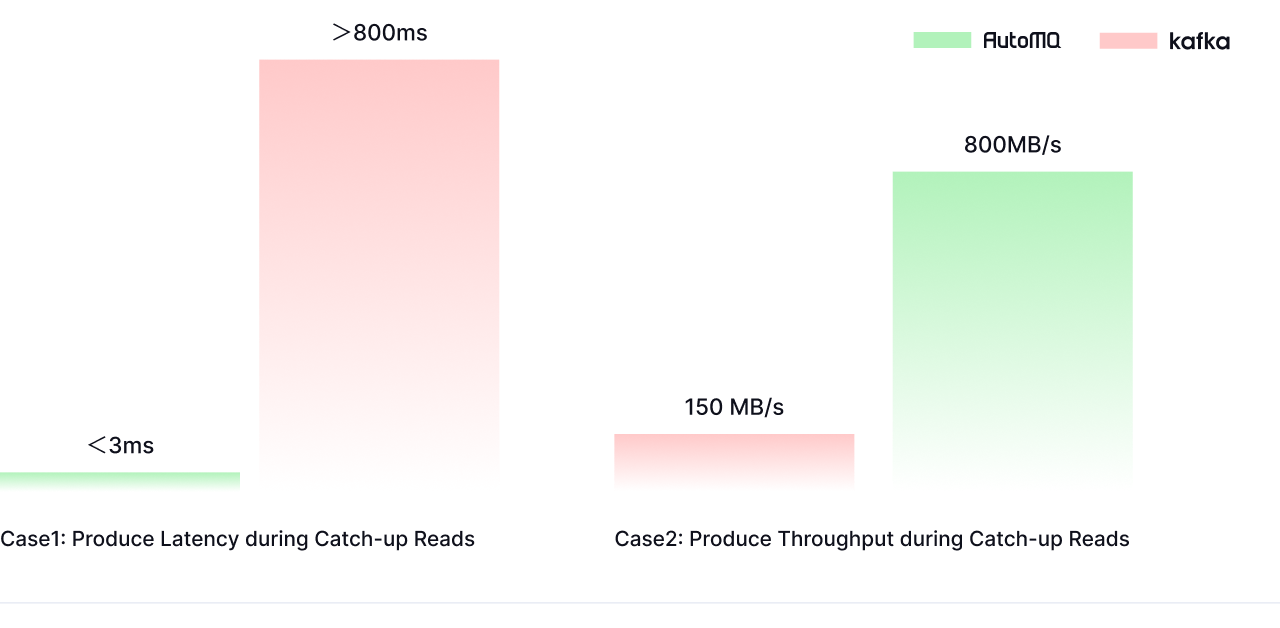
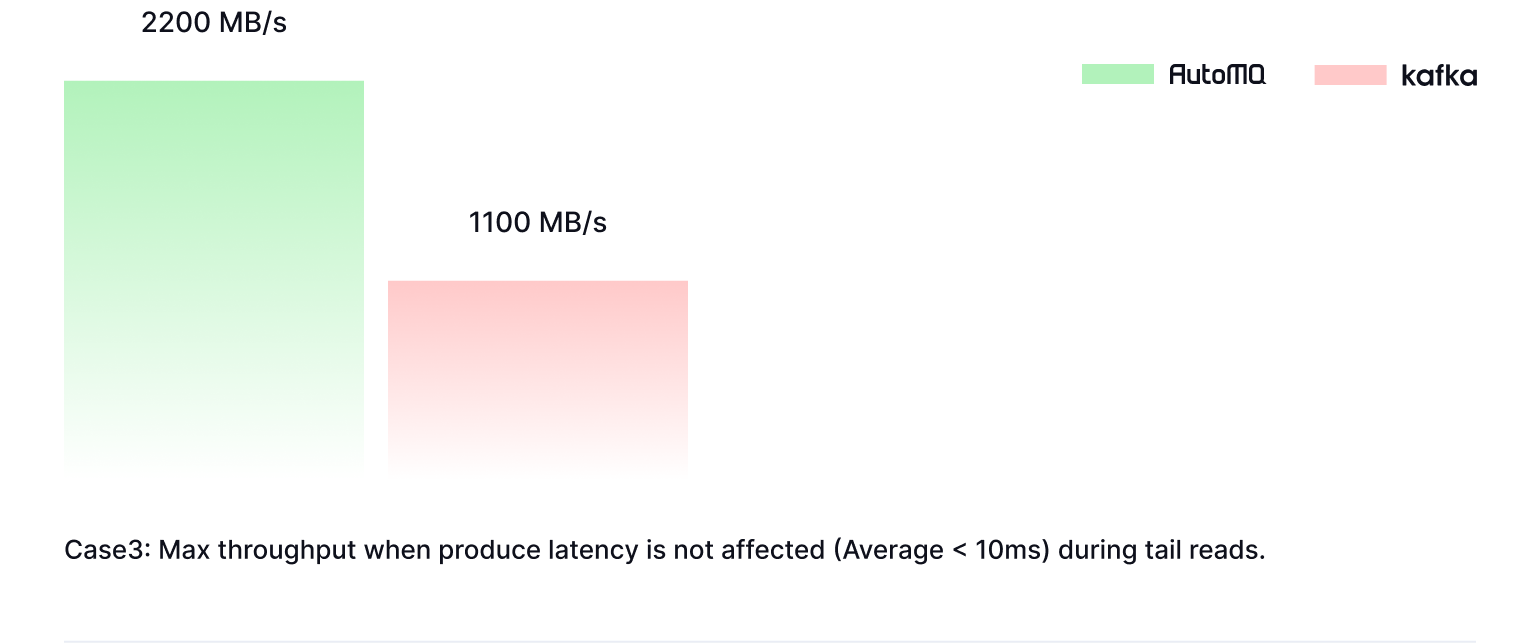
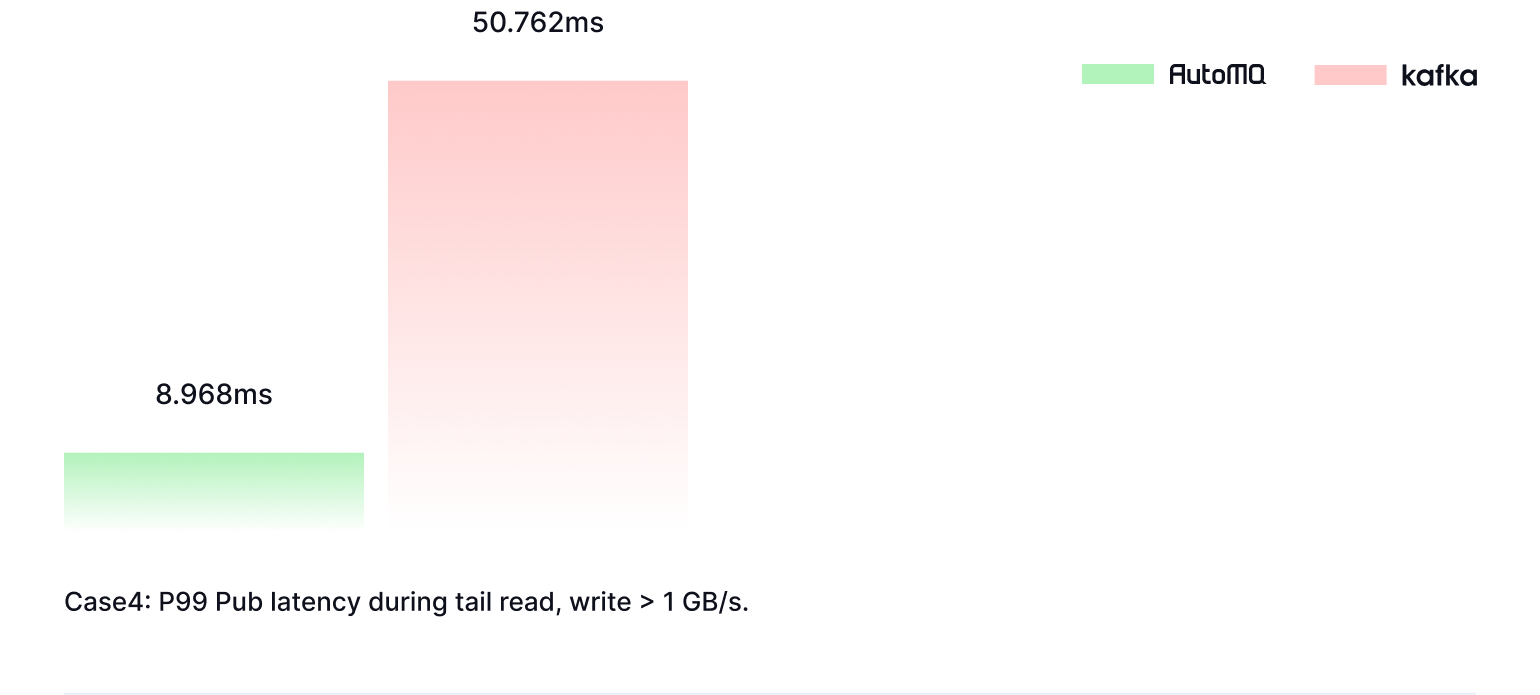
Disk Read Limitations
Reading historical data in Apache Kafka can severely impact write performance due to Page Cache pollution. This degradation not only affects Kafka itself but also propagates issues to upstream and downstream systems.

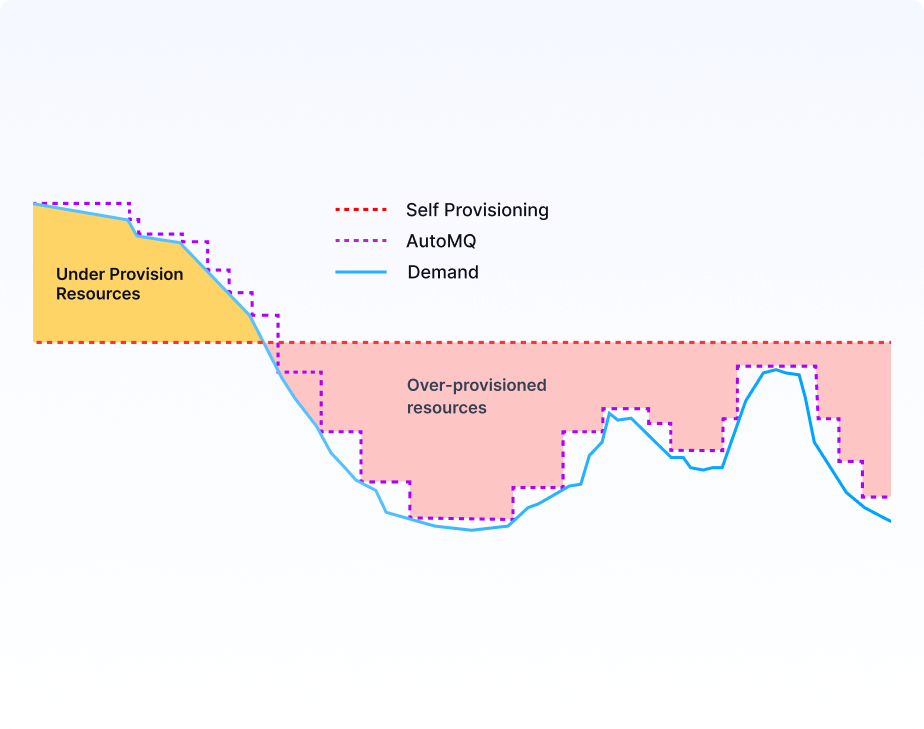
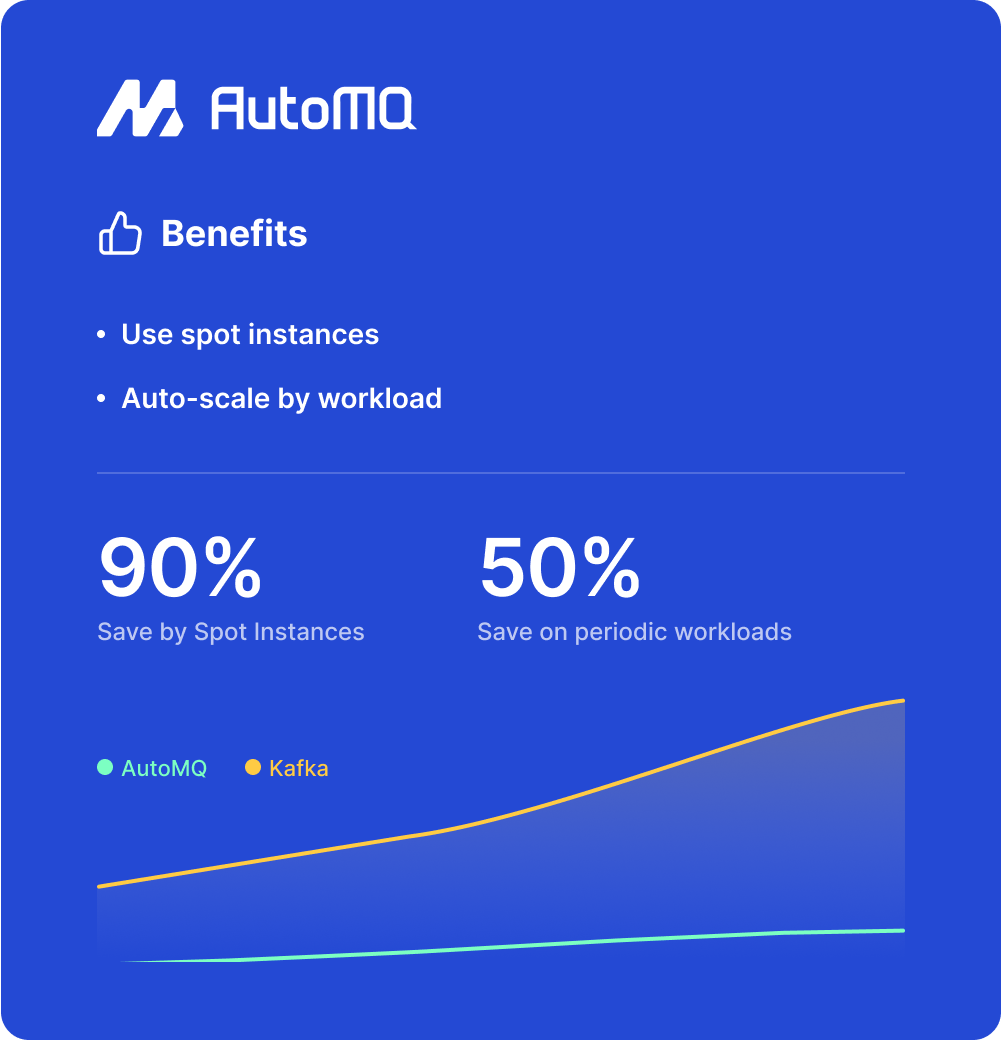
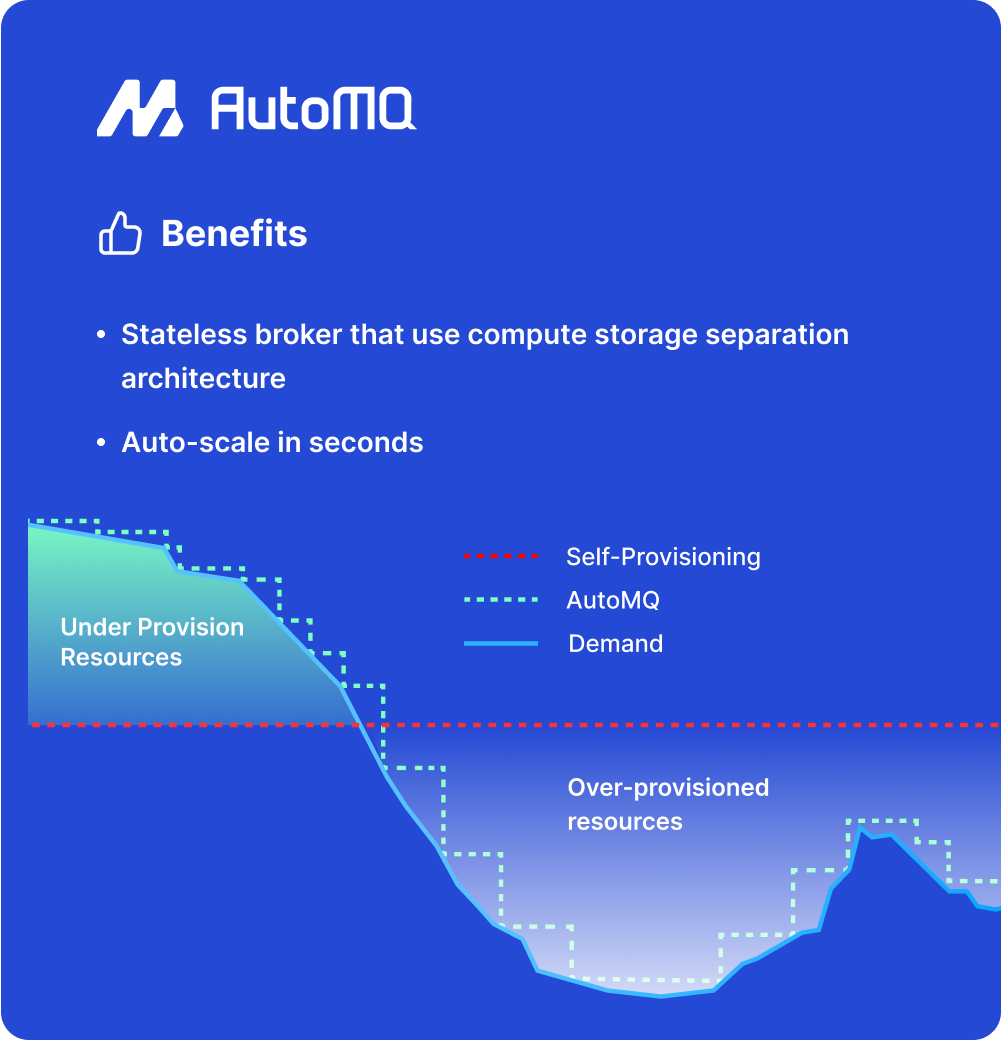
Inefficient Resource Usage
Kafka’s tightly coupled storage and computation model lacks elasticity. Users must often over-provision to meet peak demands, resulting in significant resource wastage. Moreover, data skew and uneven traffic can lead to further inefficiencies and underutilized resources within the cluster.